Java并发之ConcurrentHashMap
前言
对于HashMap,我相信大家都是了解的,我们也都知道HashMap是一个线程不安全的Map结构,如果想要使用线程安全的,我们可以考虑使用HashTable,或者使用Collections.synchronizedMap()方法,这样也能保证HashMap的线程安全,但是不要忘记我们JUC包下还有一个数据结构,就是ConcurrentHashMap这个结构其实可以简单理解为HashMap的线程安全版本,他内部也是数组+链表+红黑树,并且相较于HashTable他的效率提升是很多的,而对于ConcurrentHashMap来说,JDK7和JDK8也是不一样的,对于JDK7是采用分段锁来实现的,而对于JDK8来说是采用CAS + synchronized实现的,同样我们也把他分开来叙述
JDK7之前
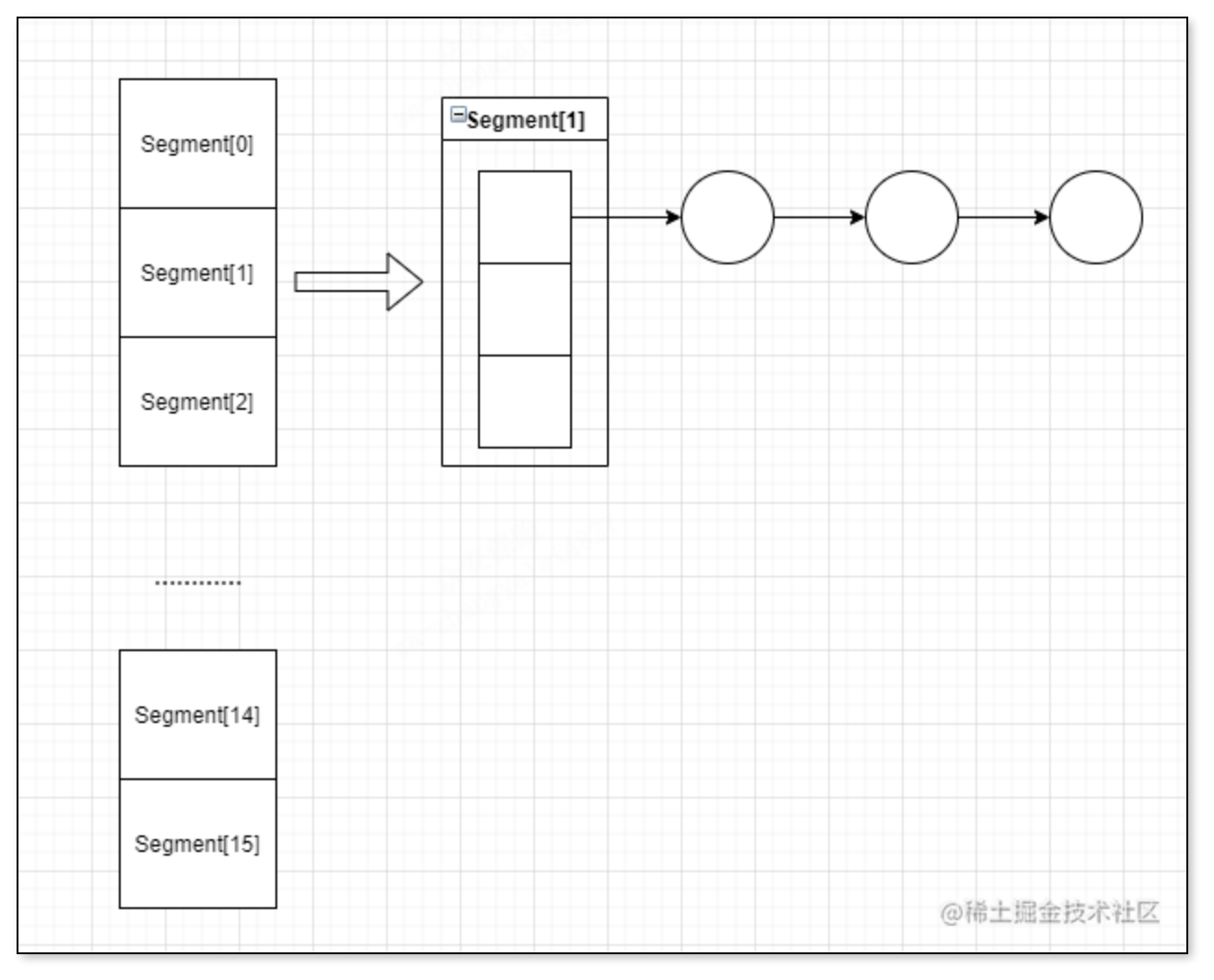
我们前面已经说了,在JDK7之前是采用分段锁来完成的,其实JDK7之前的ConcurrentHashMap可以看成一个Segment数组,里面每一个Segment包含这一段哈希桶,其实这样说不好理解,我们知道HashMap里面维护了一个哈希数组,而这个哈希数组里面放的是一组链表,就是这样,而ConcurrentHashMap可以理解为这把这个哈希数组分段
 然后ConcurrentHashMap是给每一个Segment加锁达到线程安全的,这个分段数量默认容量为16个,我们可以在初始化的时候给这个数量
然后ConcurrentHashMap是给每一个Segment加锁达到线程安全的,这个分段数量默认容量为16个,我们可以在初始化的时候给这个数量
初始化
对于ConcurrentHashMap的初始化,我们可以指定三个值,分别是,initialCapacity ,loadFactor,concurrencyLevel,他们分别表示初始容量,负载因子,Segment数量,这个初始容量指的是ConcurrentHashMap的容量,而这个负载因子使用的时候其实是基于分段来使用的,因为Segment数量一旦确定,就固定了,不能改变,而这个负载因子是给每个Segment来使用的。
put方法
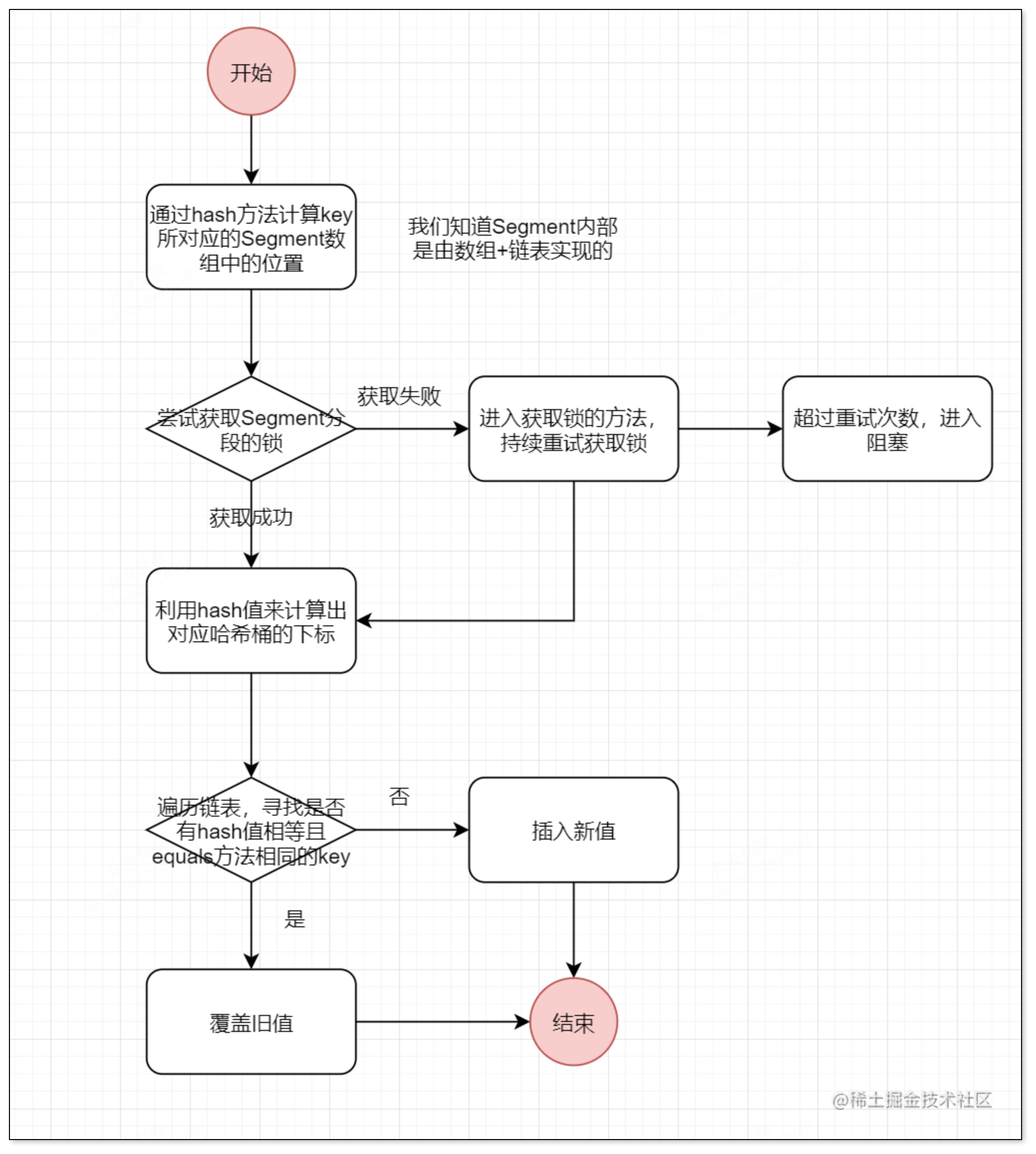 大体流程为:我们先通过hash方法计算出对应Segment段,然后尝试获取该分段的锁,如果能拿到就去添加这个k-v,如果没有拿到会持续重试获取该锁,重试阶段拿到锁后继续执行,如果超过了重试次数,就会阻塞,这里我并没有写扩容机制,扩容机制我放到后面去叙述,扩容机制的前提也是拿到分段锁!
大体流程为:我们先通过hash方法计算出对应Segment段,然后尝试获取该分段的锁,如果能拿到就去添加这个k-v,如果没有拿到会持续重试获取该锁,重试阶段拿到锁后继续执行,如果超过了重试次数,就会阻塞,这里我并没有写扩容机制,扩容机制我放到后面去叙述,扩容机制的前提也是拿到分段锁!
get方法
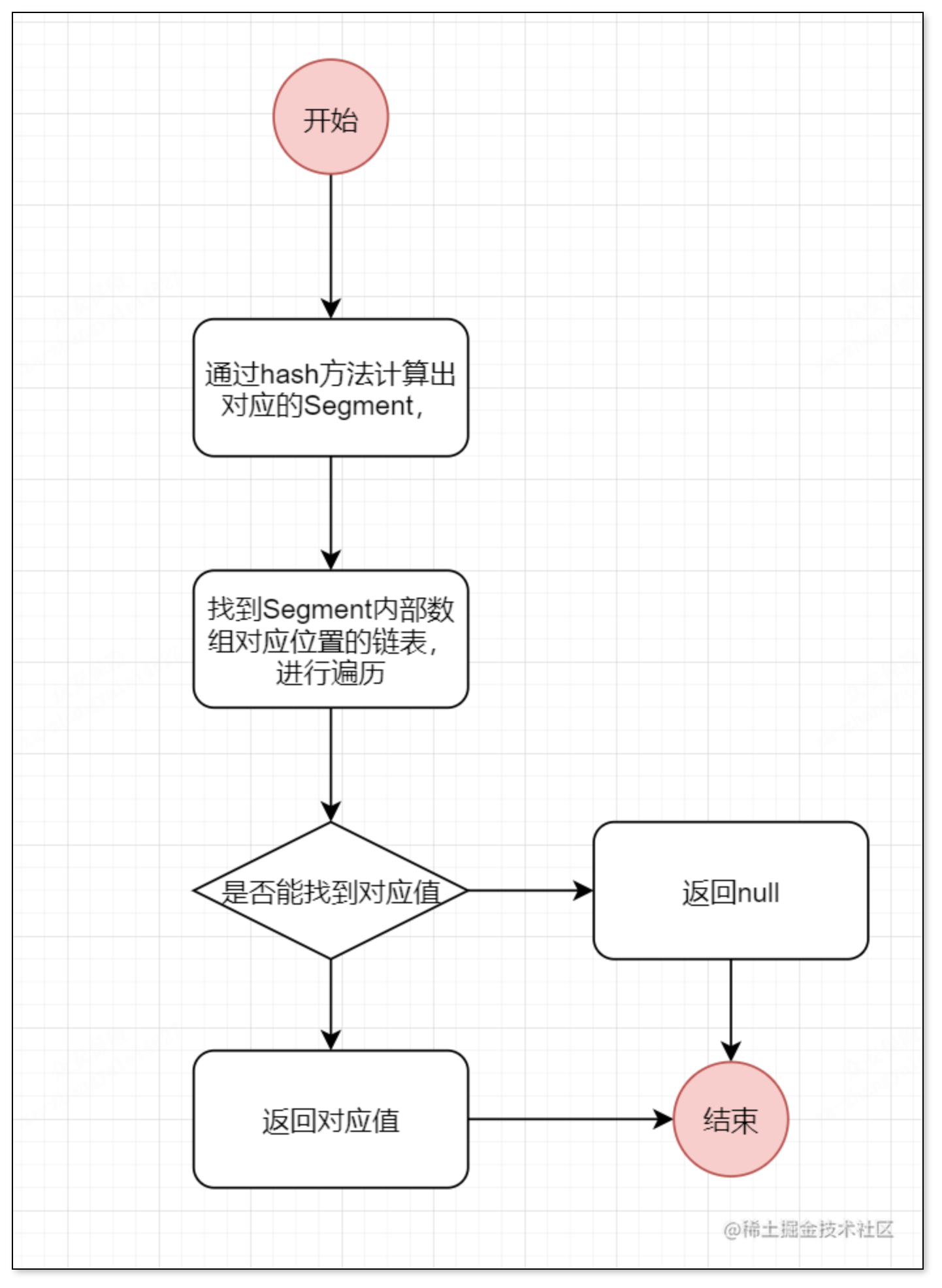
大致流程:我们先通过hash方法计算出对应Segment段,然后再找到Segment对应的哈希桶,然后去遍历链表
扩容机制
在说扩容机制前提一下,Segment数组不能扩容,扩容扩的是扩大的每个Segment对应的哈希桶的长度,扩容之后,容量变为之前的2倍,然后生成一个新的哈希桶,然后再重新计算每个节点哈希值
并发分析
我们看到get方法是没有去添加锁的,也就是像put方法去给Segment段去加锁,这样可能就会出现问题,也就是并发问题
如果我们先去get然后再去put这样是不会有问题的,但是如果先去put然后再去get这样可能会出现问题,这个时候volatile字段就显现出来作用了,在ConcurrentHashMap中的哈希桶是用了这个关键字来达到可见性
JDK8之后
我们都知道JDK8之后HashMap的数据结构发生了改变,从数组+链表 -> 数组+链表+红黑树,同样的,ConcurrentHashMap也在这方面进行了改变,在JDK8中,直接放弃了JDK7之前的做法,也就是直接放弃了分段锁,而采用了,CAS + synchronized模式
初始化
对于JDK8之后的ConcurrentHashMap的构造方法,他需要一个参数,也就是initialCapacity,这个参数指定是固定为0.75,在开始看源码的时候,我还以为ConcurrentHashMap和HashMap一样都是可以指定负载因子的,结果并没有在构造中找到指定负载因子的构造方法,并且发现,这个值直接指定了,这与HashMap不一样,而具体原因我也不太明白,不太明白为什么不允许去指定这个负载因子了,如果有人知道,求指教
put方法
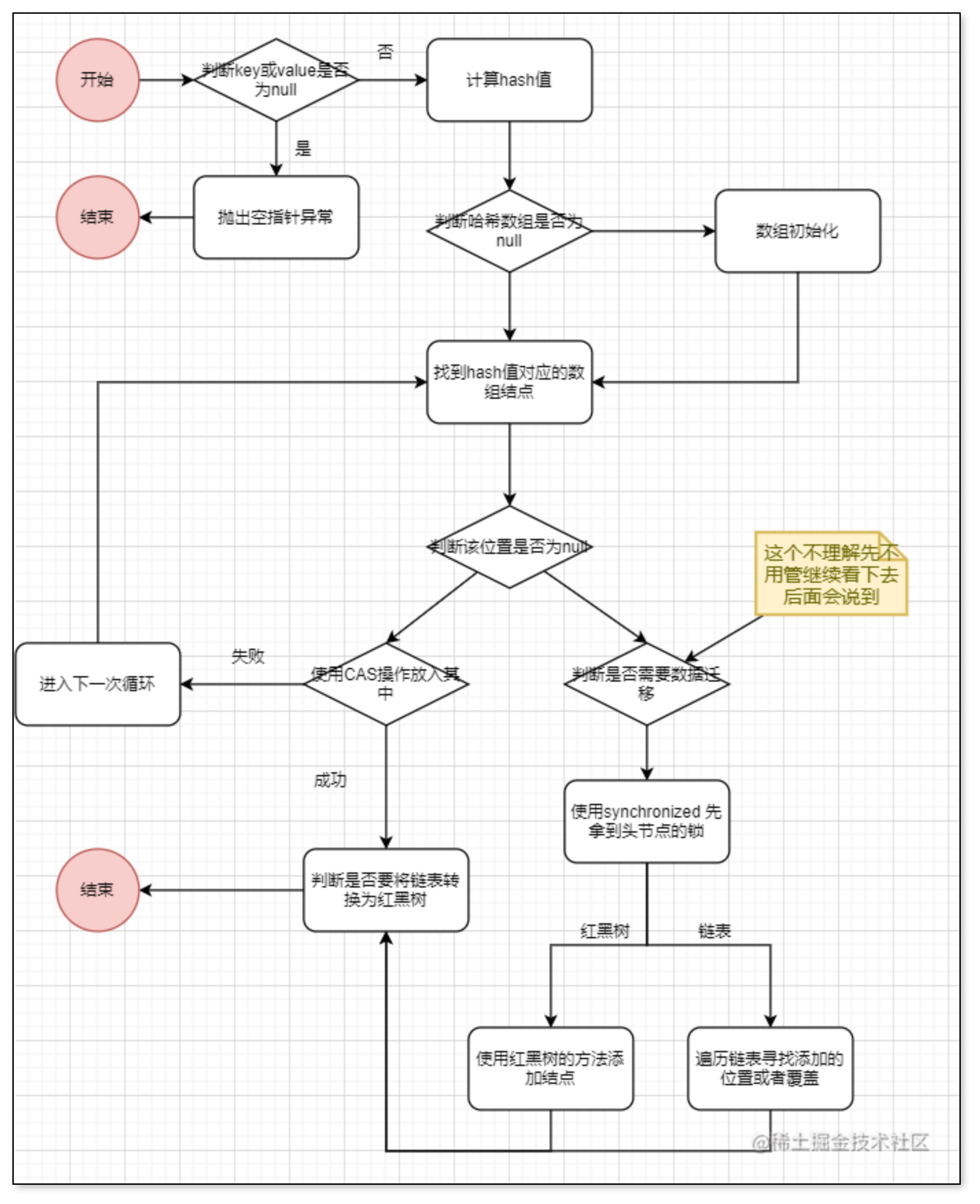
这里我说一下具体为什么key或value不能为null,先说结论那就是会出现二义性问题,因为我们在并发场景下,我们调用map.get(key)如果map中没有这个key-value,那么还是会返回null,如果key为null,value不为null,会返回value的值,但是我们如果调用map.containsKey(key)这个方法,我们会发现如果map中没有这个key-value会返回false,但是如果key为null,但是value不为null会返回true,这就出现了问题
这样子说可能会有一些难以理解,我来举个例子
//先创建一个map
HashMap<Integer,Integer> map = new HashMap<>();
map.get(1);//这个时候hashmap中不存在1这个key,返回null
map.containsKey(1);//这个时候返回false没有什么疑问
map.put(1,null);//我们添加了一个1-null的这样一个k-v键值对
map.get(1);//这个时候hashmap中存在1这个key,但是对应的value仍然为null,返回null
map.containsKey(1);//这个时候存在1这个key所以要返回true
所以,当我们get到的value为null的时候,我们并没有办法确定到底是因为map中不存在这个k-v或者是因为对应这个k的v就是null,我们知道ConcurrentHashMap是线程安全的,所以我们并不能确定在get方法和containsKey方法之间没有其他线程捣乱,所以干脆直接禁止了
我们在流程图里面,并没有看到扩容的流程,我们知道ConcurrentHashMap和HashMap一样,都是链表长度大于8并且数组长度达到64的时候会进行红黑树转换,其实这个扩容操作是融合到判断是否将链表转换为红黑树里面了,有些人可能会好奇,这里我先不去说,我们后面细细道来他的扩容机制
初始化数组initTable方法
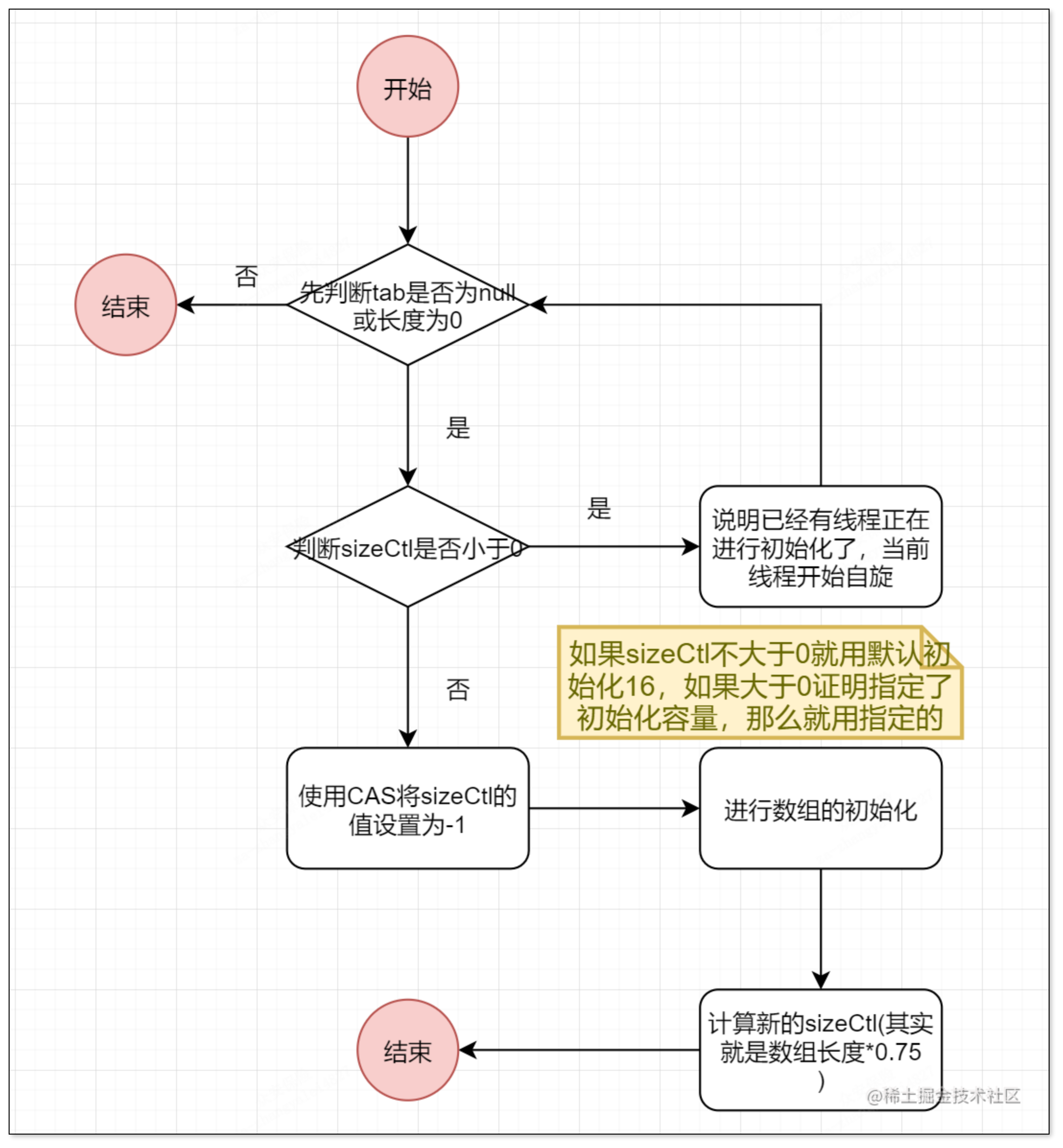
其实这个sizeCtl成员变量有多种情况,这里我说一下,大体分为三种情况小于0,等于0,大于0
- 小于0
小于0并且等于-1,那么证明数组正在进行初始化
如果小于0并且不等于-1,那么就说明数组正在进行扩容,sizeCtl = -(1 + n),有n个线程在帮助扩容
- 等于0
证明初始化的时候要使用默认的大小也就是16
- 大于0
如果数组未进行初始化,这个值就是初始化容量,如果数组已经初始化,这个值就是扩容阈值
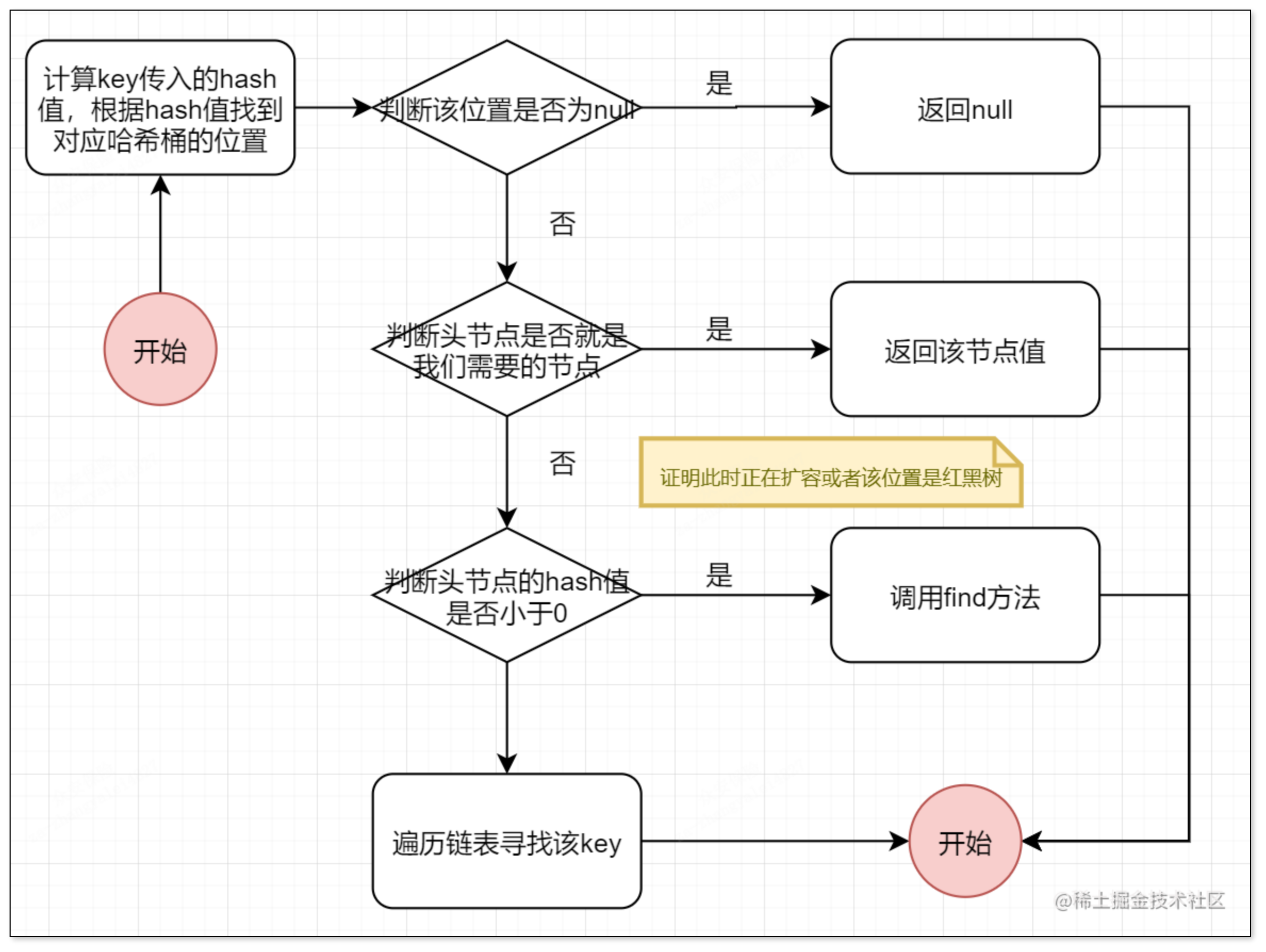
get方法
链表转换红黑树
在说扩容之前我们先说一下ConcurrentHashMap中的链表转换红黑树的方法,也就是treeifyBin这个方法,我们直接看一看他的流程
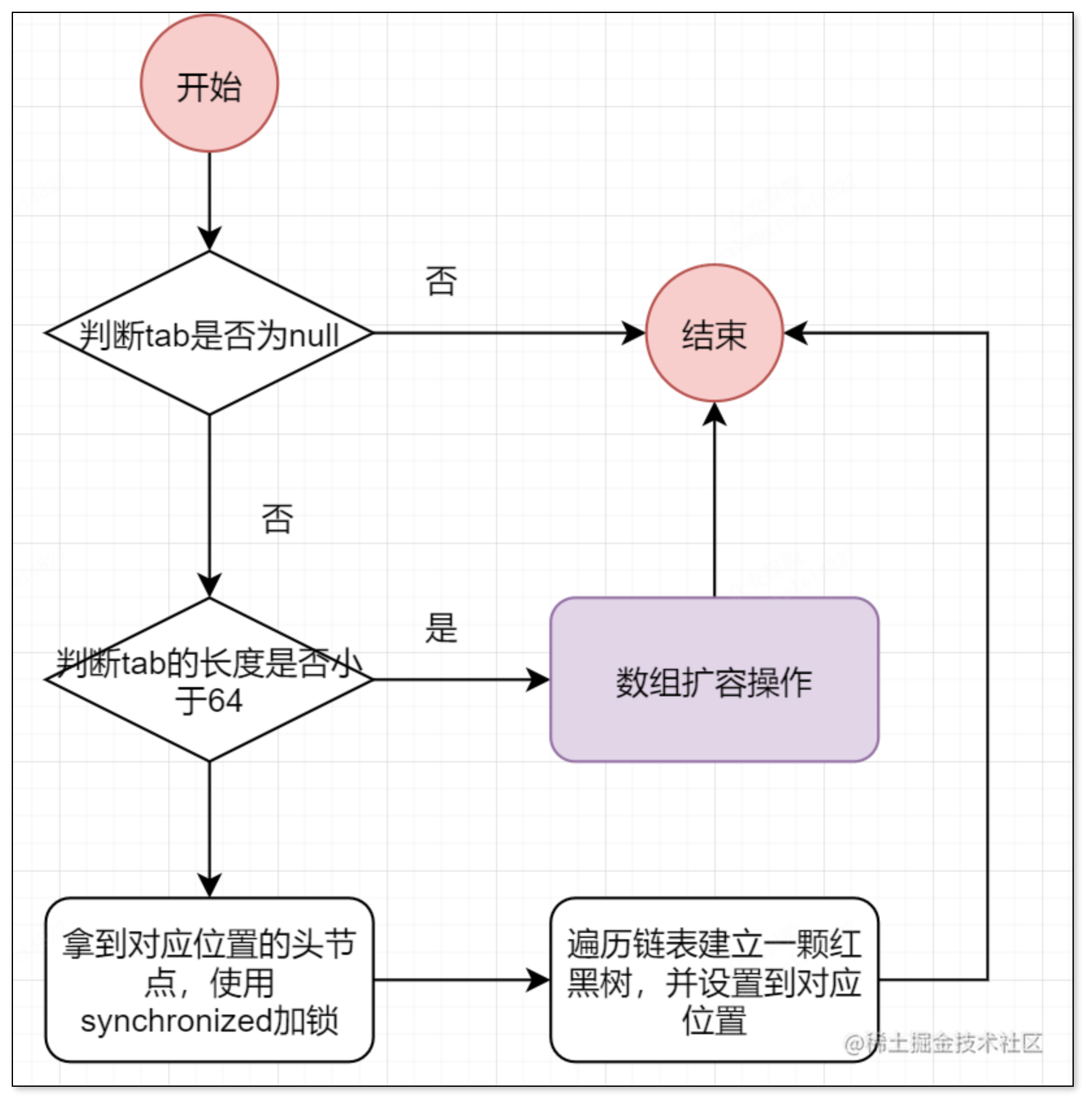
我们可以看到链表转红黑树方法中,会先判断是否达到树化阈值,如果未达到就先进行扩容,也就是先执行tryPresize这个方法,否则就加锁进行树化操作
扩容操作
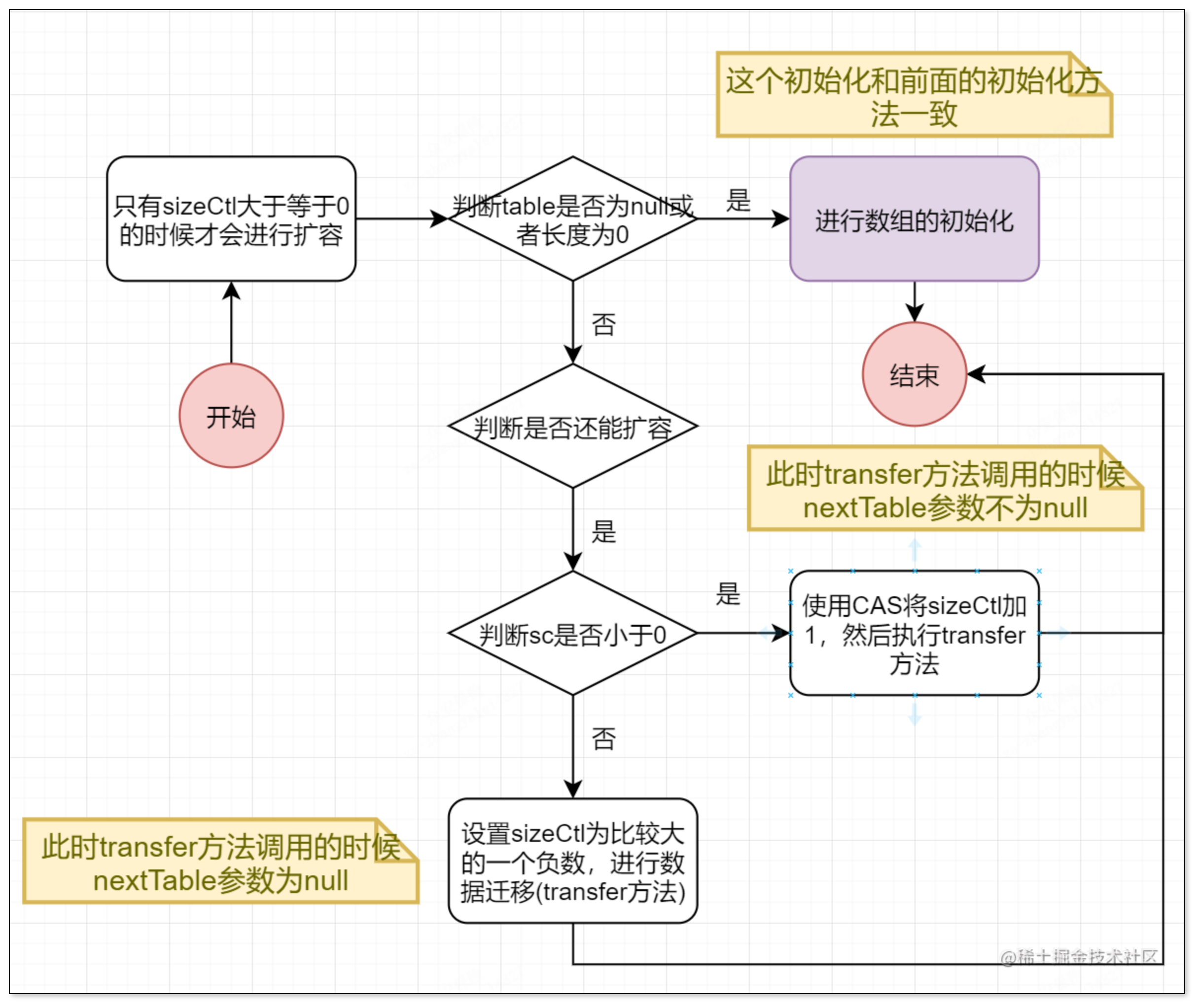
这个方法的核心是操作sizeCtl属性,第一次进入的时候将sizeCtl字段设置为一个比较大的负数,再调用transfer(tab,null),然后接下来的方法通过每次将sizeCtl字段加1,然后调用transfer(tab,nt)方法
疑问?
我在看源码的时候,不是很明白为什么将sizeCtl设置为一个比较大的负数之后仍然会进入该循环该循环的条件不是sizeCtl大于等于0吗?如果有清楚的兄弟请告知!
数据迁移
数据迁移是并发HashMap中最难的一个部分了,其实就是transfer(tab,nextTab)方法,这个方法的作用是,将tab数组的部分元素迁移到nextTab数组中,其他方法调用这个方法的时候,会保证第一次调用的时候传入的nextTab为null,这也保证了让多个线程去共同扩容,他在第一次调用这个方法的时候会给sizeCtl设置一个不等于-1的负数,我们前面已经说过这个负数的意思了,然后会去计算一个步长,这个步长的作用是为了给每个线程去分片来保证数据迁移正确,也就是说不能让迁移过后的节点再迁移一次,这里使用的是一个ForwardingNode类,如果原数组该位置已经迁移过了,那么就直接替换为这样的一个类,这样也很好的和前面形成了闭环,就是在put方法的时候会进行一个判断如果该节点正在迁移,那么线程会去帮助迁移
总结
对于JDK7之前的并发Map,采用的是分段锁来保证线程安全的,这样会导致效率十分低下,因为锁住的一个段,也就是哈希桶的一段
对于JDK8之后的并发Map,采用的是CAS+synchronized来保证线程安全的,里面最为难的就是数据迁移这个方法,只要这个方法理解了,其他的也就容易理解了,在这里使用synchronized是为了锁住某一个哈希桶的节点,而不像JDK7之前直接把好几个哈希桶通通锁住,这样效率提升了很多
💬 评论区