前言
我们在Java中经常使用Map结构,Map的本质是k-v键值对,而HashMap更是我们经常用的Map实现类的一种,HashMap的实现并不是同步的,证明它不是线程安全的,它的key和value都可以为null,并且HashMap中的k-v键值对也不是有序的
hashCode方法和equals方法
说到HashMap就不得不提到hashcode方法和equals方法,因为在我们存储的时候,我们的k值是通过hashCode方法来决定的,我们可以称这种结构为哈希桶。
话不多说我们直接看代码
这里我创建了一个重写过hashCode方法的yl类
public class yl {
@Override
public int hashCode() {
return 1;
}
}
然后编写了一个测试
public static void main(String[] args) {
HashMap<yl,Integer> map = new HashMap<>();
map.put(new yl(), 1);
map.put(new yl(), 2);
System.out.println(map);
//{yl@1=1, yl@1=2}
}
我们发现返回相同的hashCode值的对象不会被覆盖,两个yl对象都正常的存入了map中
我们将重写的hashCode方法注释掉,然后重写equals方法,让equals方法默认返回true
@Override
public boolean equals(Object obj) {
return true;
}
编写测试类
public static void main(String[] args) {
HashMap<yl,Integer> map = new HashMap<>();
map.put(new yl(), 1);
map.put(new yl(), 2);
System.out.println(map);
//{yl@15db9742=1, yl@6d06d69c=2}
}
我们发现equals方法返回值相同的值也不会被覆盖,两个yl对象都成功存入了map
接下来我们将hashCode方法的注释去掉
再编写一个测试
public static void main(String[] args) {
HashMap<yl,Integer> map = new HashMap<>();
map.put(new yl(), 1);
map.put(new yl(), 2);
System.out.println(map);
//{yl@1=2}
}
我们发现重写玩equals方法和hashCode方法之后,第二个yl对象将第一个yl对象覆盖了,两个yl对象不能同时存入map当中
当仅仅重写过equals方法或者hashCode方法之后,对象还是能正常的存入map集合中 当同时重写equals方法和hashCode方法之后,对象就不能被正常的存入map集合中了
JDK8之前的HashMap
在JDK8之前版本的HashMap,底层的实现使用的是数组+链表,大概就是下面图这样子
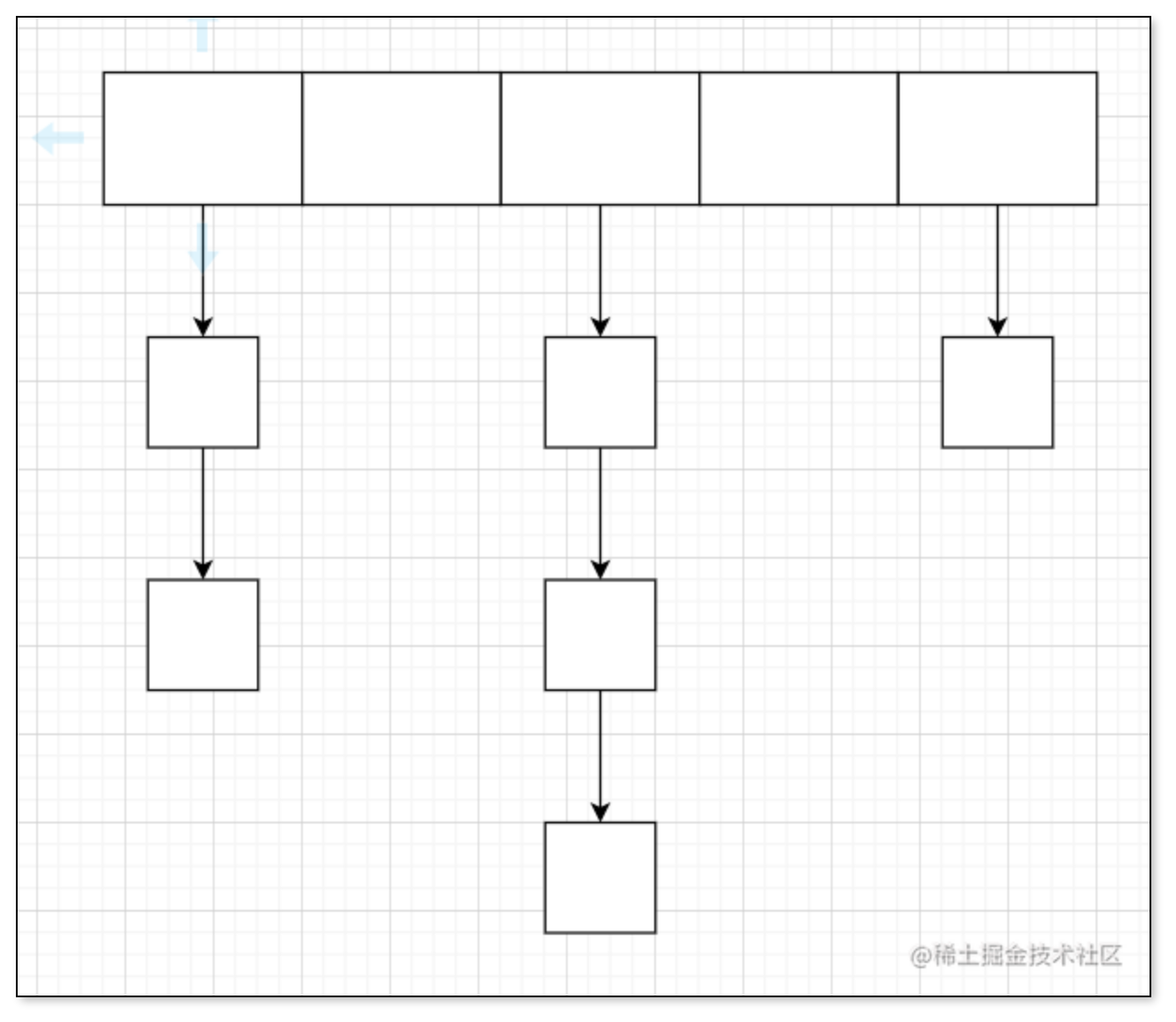
我们有一句俗语,叫做前七后八
意思就是JDK7及之前版本的HashMap使用的都是头插法,而JDK8及之后的版本使用的都是尾插法,这里我们先讲JDK7版本的HashMap。
成员变量
//用于存储数据的核心成员变量
transient Entry<K,V>[] table;
//HashMap的键值对数量
transient int size;
//装载因子,用于决定table的扩容量
final float loadFacotr;
table是HashMap最核心的成员变量,因为该数组记录了HashMap的所有数据,它的每一个下标都对应着一个链表,为什么是一个链表呢,链表是为了解决哈希冲突问题。
所以我们可以知道,我们在HashMap中的所有操作,其实都是在操作table数组
HashMap规定了table数组的两个特性:根据需要来进行扩容、table数组的长度始终都是2的次方
我们都知道,在数组中查找一个值的时间复杂度为O(1),而在链表中查找一个值的时间复杂度为O(n),所以我们知道,要尽量少用链表,多使用数组,这样会使HashMap的查找效率提高,而在table数组中,索引值是根据hashCode值而来,所以我们需要使hashCode值尽可能分散,这样才能使HashMap的查找效率变高
常量
//默认初始化容量,这个值必须是2的次方
static final int DEFAULT_INITIAL_CAPACITY = 16;
//最大容量,在构造函数指定HashMap容量的时候,用于做比较
static final int MAXIMUM_CAPACITY = 1 << 30;
//默认的加载因子大小,如果在构造函数没有指定该值的大小,将使用该值
static final float DEFAULT_LOAD_FACTOR = 0.75f;
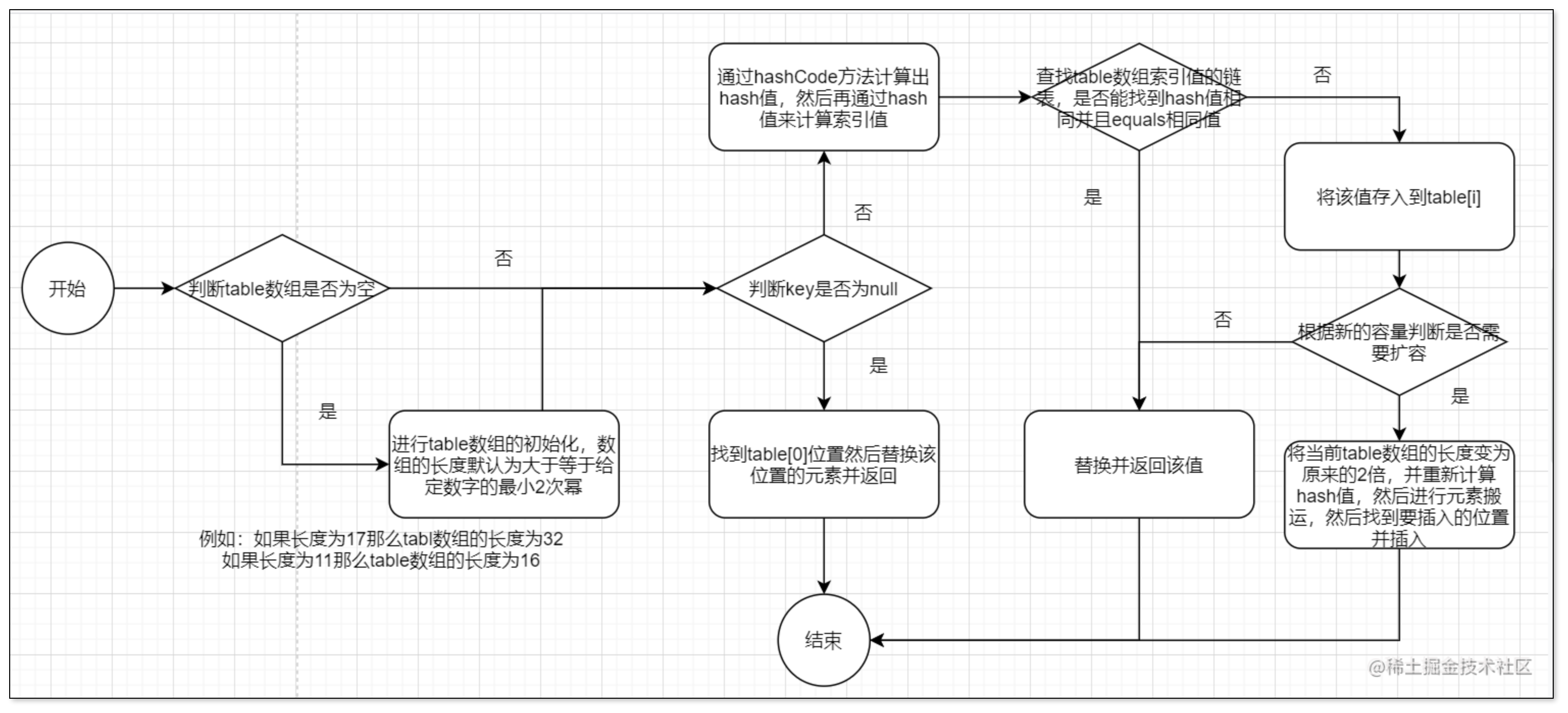
put方法
HashMap的put方法可以说是我们经常使用的方法之一了,它的实现是很复杂的,整个流程大概为:
-
计算key的hash值
-
根据hash值和table的长度来确定下标位置
-
将值存入数组
-
根据key值和hash值来进行对比,确定是创建链表结点还是替代之前的链表值
-
根据增加后的size来进行扩容,确定下一个扩容阈值,确定是否需要使用替代哈希算法
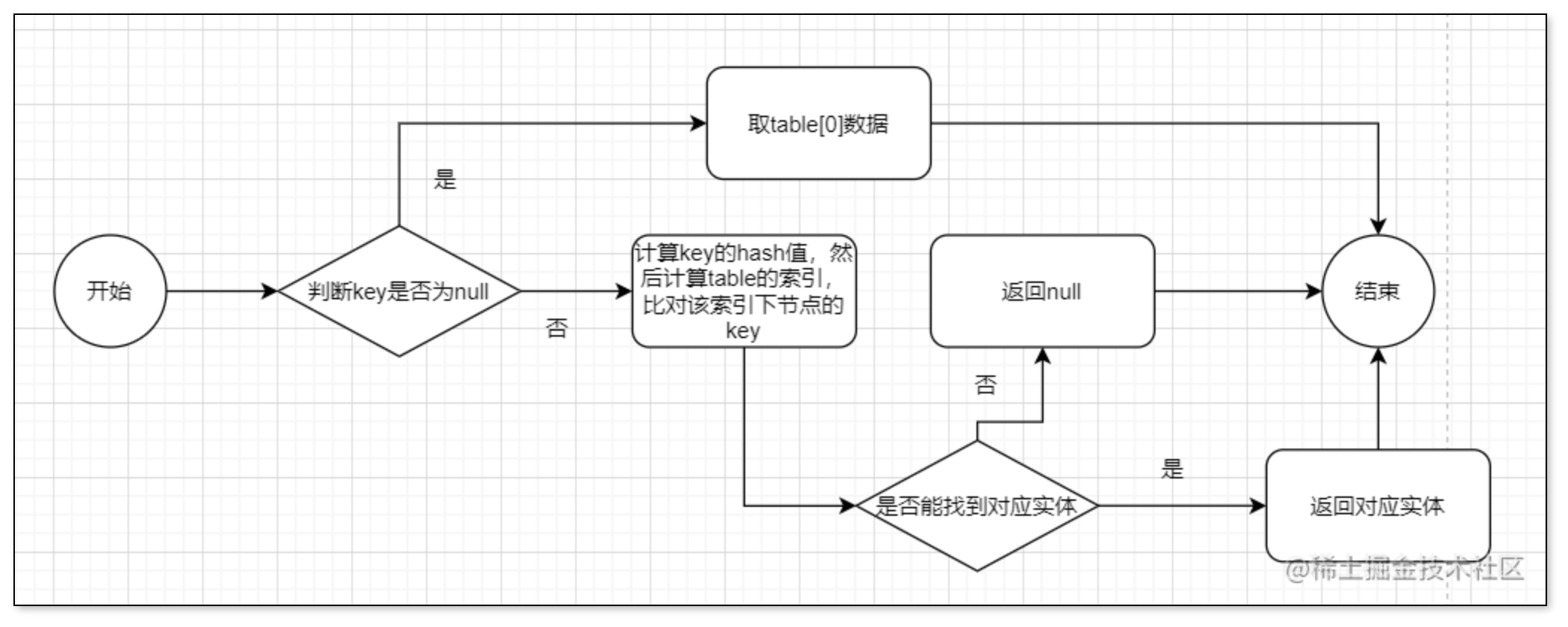
get方法
相较于put方法,get方法就相对简单一点了,整个流程大概为:
-
判断key值是否为空
-
为空:取table[0]数据返回
-
不为空:先计算key值的hash值,然后根据hash值计算出在table数组中的索引,与链表下的key一一对比
-
能找到对应实体,返回对应实体
-
不能找到对应实体,返回null
-
-
扩容机制
扩容是HashMap比较重要的一个点了,在JDK7中扩容是比较简单的
我们可以在实例化的时候给构造函数传、容量、装载因子、阈值这些值,如果我们没有设置这些值,我们就会使用默认值
我们第一次put时,会初始化数组,容量不小于指定容量的2的幂数。然后根据负载银子确定阈值(阈值 = 装载因子 × 容量)
如果我们不是第一次扩容,则新容量 = 旧容量 × 2 ,新阈值 = 新容量 × 装载因子
JDK8及之后的HashMap
Java 8的HashMap的数据结构发生了很大的变化,之前的HashMap使用数组+链表来实现,在Java 8中底层使用数组+链表/红黑树实现,新的HashMap中仍然使用的是table数组,不过table数组的数据类型发生了变化
transient Node<K,V>[] table;
常量和成员变量
//序列化版本号
private static final long serialVersionUID = 362498820763181265L;
//默认容量为16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
//最大容量为2的30次方
static final int MAXIMUM_CAPACITY = 1 << 30;
//默认装载因子为0.75
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//树化阈值,当哈希桶中的元素个数大于等于8的时候转换为红黑树
static final int TREEIFY_THRESHOLD = 8;
//树降级为链表的阈值,当哈希桶中的元素个数小于等于6的时候转换为链表
static final int UNTREEIFY_THRESHOLD = 6;
//当哈希桶的个数达到64的时候进行树化
static final int MIN_TREEIFY_CAPACITY = 64;
//核心成员变量table用于存储数据
transient Node<K,V>[] table;
//作为entrySet()的缓存
transient Set<Map.Entry<K,V>> entrySet;
//table中元素的个数
transient int size;
//修改次数
transient int modCount;
//扩容阈值 threshold = loadFacotr × capacity
int threshold;
//装载因子
final float loadFactor;
我们发现JDK8的HashMap相较于JDK7有很大变动,无论是table数组的数据类型还是HashMap的成员变量上,都多了很多。
-
容量
容量为哈希桶的数量,也就是数组的长度,默认为16,最大值为2的30次方
-
loadFactor 装载因子
这个变量相较于JDK7并没有太大的变化,这个变量用于确定阈值,而阈值与扩容有关,当容量达到一定的时候,HashMap会触发扩容机制(阈值 = 容量 × 装载因子),我们可以在实例化的时候通过构造函数设置该值,如果不设置那么默认为0.75
-
树化
在JDK7中完全没有这个概念,这是在JDK8中出现的,当容量达到64并且链表的长度达到8的时候会进行树化操作,会将链表转换为红黑树,而当链表的长度小于等于6的时候会从红黑树转换为链表
put方法
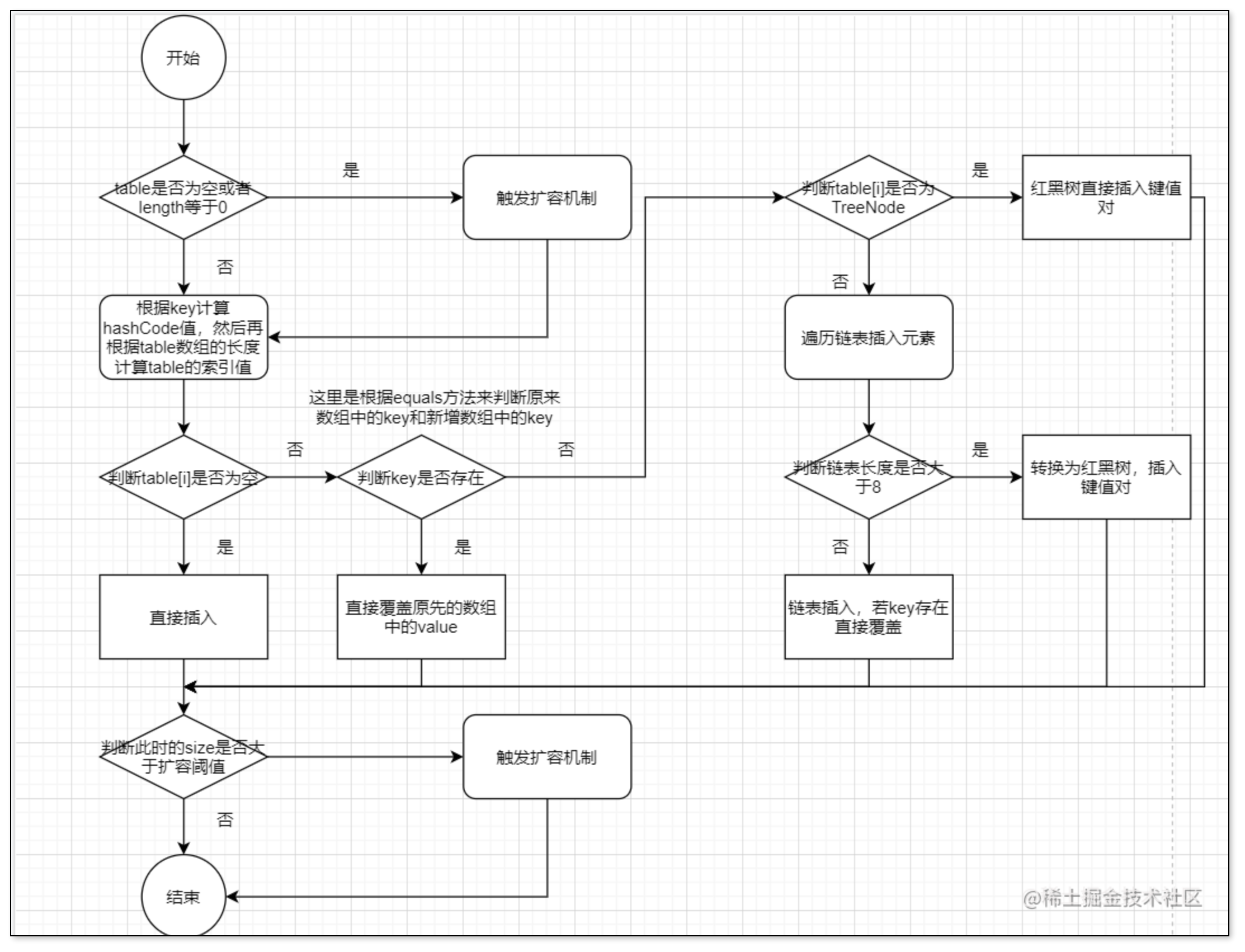 其实相较于JDK7 HashMap的put主要就是加入了红黑树这一数据结构,其实大概的流程就是这样:
其实相较于JDK7 HashMap的put主要就是加入了红黑树这一数据结构,其实大概的流程就是这样:
-
先判断table是否为空,如果为空则触发扩容,
-
然后根据传入的key值计算hashCode值,再根据hashCode值和数组的长度计算下标
-
然后保存数据(保存数据又可以分为很多种情况)
-
当数组下标位置没有结点的时候,直接添加一个Node结点
-
当数组下标位置为树结点(TreeNode)的时候直接添加一个树节点
-
当数组下标位置有结点,并且不是树节点而是链表结点的时候,此时会遍历链表根据hashCode值和equals方法来判断是否重复(这点和JDK7中相同),决定此时是添加新节点或者更新原结点
-
当添加了链表结点之后,会进行扩容的判断,当链表的长度达到8并且哈希桶的数量达到64的时候,这个时候会进行树化操作,将原先的链表转化为红黑树。
-
get方法
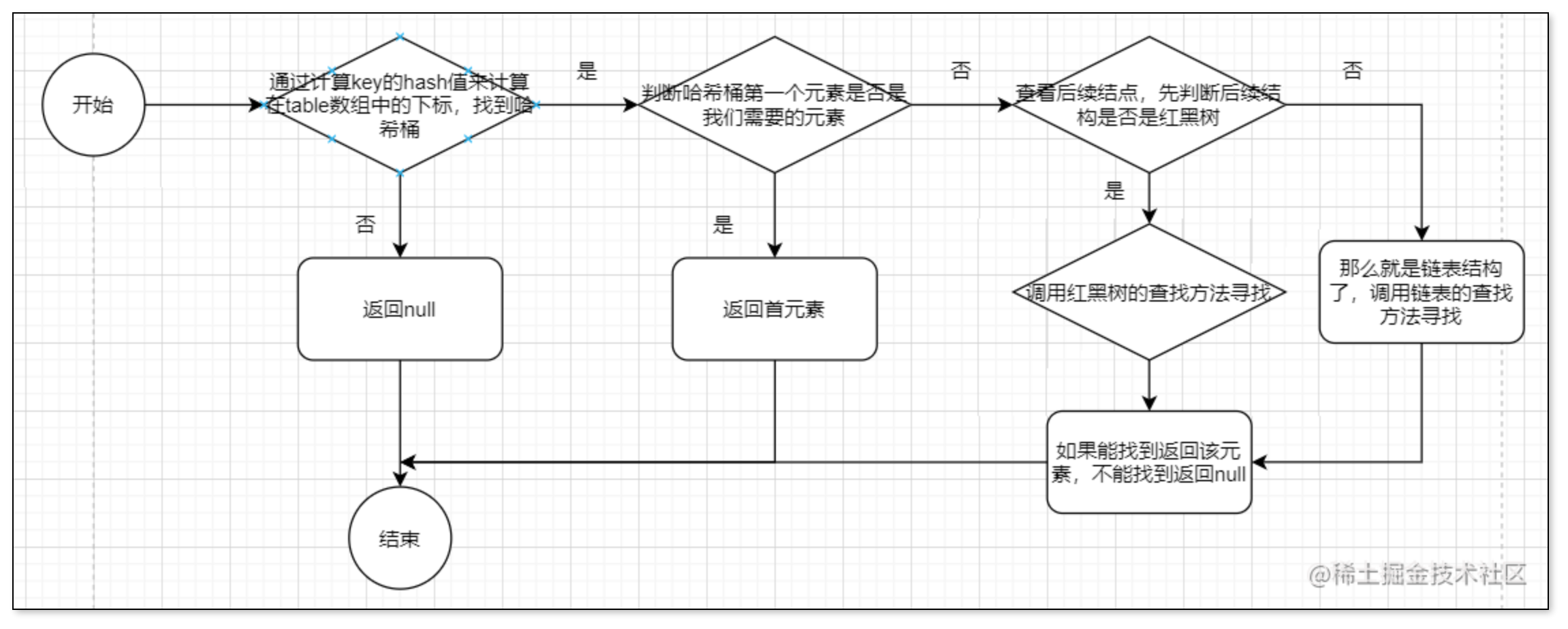
大概的流程为:
-
通过key的hash值来计算table数组的下标,找到哈希桶
-
如果哈希桶上的key就是需要的,那么直接返回
-
如果不是那么查看后续节点
-
如果后续结点是链表,那么就遍历链表来寻找
-
如果后续结点是红黑树,那么就调用红黑树的方法寻找
-
-
如果没有找到那么返回null
扩容机制
相较于JDK7的扩容机制,JDK8的扩容机制是相对麻烦的。
在了解扩容之前我们先了解一下JDK8的树化操作,在JDK8中,HashMap多了一种数据结构,那就是红黑树,那么什么时候会进行树化操作呢?
在HashMap中,table数组的长度永远是2的次方,为什么呢?
因为我们在计算数组下标的时候,需要使用到容量,如果这个值不是2的次方,那么很容易造成哈希冲突,这样做也是为了减少哈希冲突。
如果我们在,构造函数中设置了容量例如10,但是table数组的长度会找到大于这个数字并且是最小的2的次方。
接下来我们再说一下树化和反树化
其实很简单,树化就是指将链表转化为红黑树,反树化就是将红黑树转换为链表
而什么时候树化和什么时候反树化就显得尤为重要了
树化条件:
哈希桶的数量达到64,并且链表的长度达到8,这个时候才会树化
反树化条件:
当一个哈希桶上的元素小于等于6的时候会进行反树化操作
说完这些我们再来叙述扩容
当HashMap的元素个数达到扩容阈值的时候,这个时候会扩容,扩容为原先的二倍,然后重新计算新的扩容阈值(扩容阈值 = 容量 × 装载因子),在由链表转换为红黑树之前,会进行判断,判断当前哈希桶的数量是否达到64,如果未达到64,会先进行扩容,不会在此时转换为红黑树
总结
-
HashMap是一种散列表是无序的,底层使用数组+链表/红黑树实现
-
HashMap是一种线程不安全的容器
-
HashMap中哈希桶的初始默认容量是16,默认装载因子为0.75,哈希桶的容量始终为2的n次方
-
HashMap中当哈希桶的数量小于64的时候,不会优先触发树化机制,而会优先采用扩容机制
-
HashMap中哈希桶的元素个数小于等于6的时候会进行反树化
-
HashMap扩容的时候,总是原先容量的2倍
-
HashMap中扩容阈值为 容量 × 装载因子
💬 评论区