JDK之LinkedHashMap
前言
LinkedHashMap是一种特殊的HashMap,他同样实现了Map接口,并且他的父类是HashMap,从LinkedHashMap的名字我们就可以看出来,他是Linked HashMap的结合,说明他有HashMap的特性,同样也具有LinkedList的特性,所以LinkedHashMap可以看作是一个LinkedList版本的HashMap,也就是HashMap + 双向链表。
结构
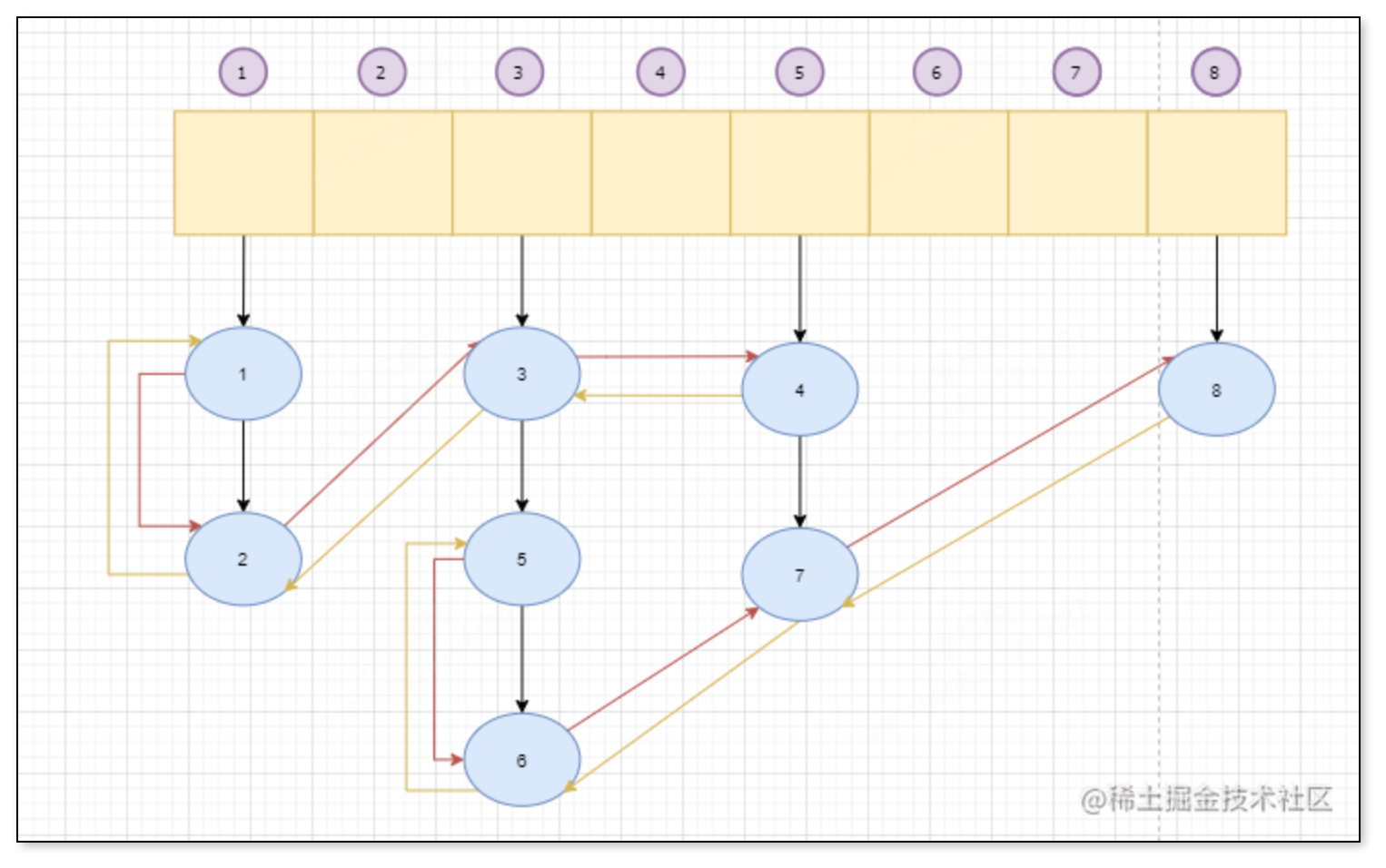 其实不难看出这就是一个双向链表+HashMap
其实不难看出这就是一个双向链表+HashMap
成员变量
//序列化ID
private static final long serialVersionUID = 3801124242820219131L;
//链表头
transient LinkedHashMap.Entry<K,V> head;
//链表尾
transient LinkedHashMap.Entry<K,V> tail;
//按照插入顺序(false)或者访问顺序(true)排序
final boolean accessOrder;
在LinkedHashMap中包含一个内部类Entry这个类继承于HashMap的Node类,该类用于保存每个元素。
构造方法
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
public LinkedHashMap() {
super();
accessOrder = false;
}
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super();
accessOrder = false;
putMapEntries(m, false);
}
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
我们可以看到这里五个构造方法,他们都是调用的父类的构造,并且除了最后一个构造方法,他们都是将排序设置为插入顺序排序,最后一个是通过自定义的,可以设置为true或者false。
核心方法
查询
LinkedHashMap的访问,主要通过迭代器进行访问,迭代器初始化的时候,默认从头节点开始访问,在迭代过程中,不断访问当前节点的after节点。
get()
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
如果查找到了元素,且accessOrder为true,则调用afterNodeAccess()方法把访问的节点移到双向链表的末尾。
新增
LinkedHashMap类的新增主要通过newNode/newTreeNode方法进行节点新增
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
//新增节点
LinkedHashMap.Entry<K,V> p = new LinkedHashMap.Entry<K,V>(hash, key, value, e);
//追加到链表的尾部
linkNodeLast(p);
return p;
}
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
//新增节点等于尾节点
tail = p;
//last为空,说明链表为空,首尾节点相等
if (last == null)
head = p;
//链表有数据,直接建立新增节点和上个尾节点之间的前后关系
else {
p.before = last;
last.after = p;
}
}
- LinkedHashMap初始化时,accessOrder为false,就会按照插入顺序提供访问,插入方法使用的是父类HashMap的put方法,不过覆写了put方法,执行中调用的是newNode/newTreeNode和afterNodeAccess 方法。
- LinkedHashMap通过新增头节点、尾节点,给每个节点增加before、after 属性。每次新增时,都把节点追加到尾节点,这样就可以保证新增节点是按照顺序插入到链表中的。
LinkedHashMap-LRU淘汰机制的实现
先说一下LRU是什么?
LRU其实就是最近最少使用,也就是说,如果容器满了, 把最近最少使用的元素给删除,在LinkedHashMap中,其实就是删除双向链表表头元素。
通过afterNodeAccess方法把当前访问节点移动到队尾,不仅仅是get方法, 执行getOrDefault、compute、computeIfAbsent、computeIfPresent、merge方法时,也会这么做, 通过不断的把经常访问的节点移动到队尾,那么靠近队头的节点,自然就是很少被访问的元素了。
LinkedHashMap本身是没有实现put方法的,调用的是HashMap的put方法,但LinkedHashMap 实现了put方法中的afterNodeInsertion方法,这个方式实现了删除操作。
LinkedHashMap和HashMap的区别
相同:他们都实现了Map接口,因此,他们都是key-value结构 所以他们的key不允许重复,而他们的value允许重复 并且可以接受null key但是只能有一个,以及null value可以有多个
不同:HashMap里面存入的键值对在取出的时候是随机的 也是我们最常用的一个Map.它根据键的HashCode值存储数据 根据键可以直接获取它的值,具有很快的访问速度。在Map 中插入、删除和定位元素 LinkedHashMap 是HashMap的一个子类,如果需要输出的顺序和输入的相同,那么用LinkedHashMap可以实现
💬 评论区