花了 500 天,从 RAG 服务到 AI Agent,到底做了什么?
写在前面
LLM(大模型)在最近几年迎来了爆炸式的增长,深处 AI 洪流,既然无法阻挡洪流,那就坦然面对洪流,毕竟大家都是普通人,顺势而为才是一个普通人该干的事情,逆风局能打,但是肯定不如顺风局来的简单。
AI 元年
这几年工作下来我一直都在跟数据打交道,第一次使用 AI 是 ChatGPT 爆火的时候,当时是 2022 年,当时 GPT 的幻觉非常严重,经常出现自己一本正经的胡说八道,不过不可置否的来说,在当时 ChatGPT 确实帮助了我写论文、查阅资料这种繁杂并痛苦的工作。
在 AI 爆火的前些年(2022、2023、2024),我确实只能算作一个使用者,无论是在 2022 年 底 ChatGPT 爆火,还是 2023 年和 2024 年,Cursor 和 Github Copilot 等等这类 AI Coding 产品横空出世,都是作为一个使用者来看待 AI、理解 AI。
2025 年,我们也加入了 AI 这场洪流,作为每天进行数据处理的工作人员,我们发现 RAG 服务与我们也牢牢相关,特别是 RAG 流程中的 Embedding(嵌入),说的通俗点就是如何让我们手头的资料、文档,变成 AI 能懂的东西,也是在这一年我们开始了 RAG 服务的第一行代码。
RAG 服务
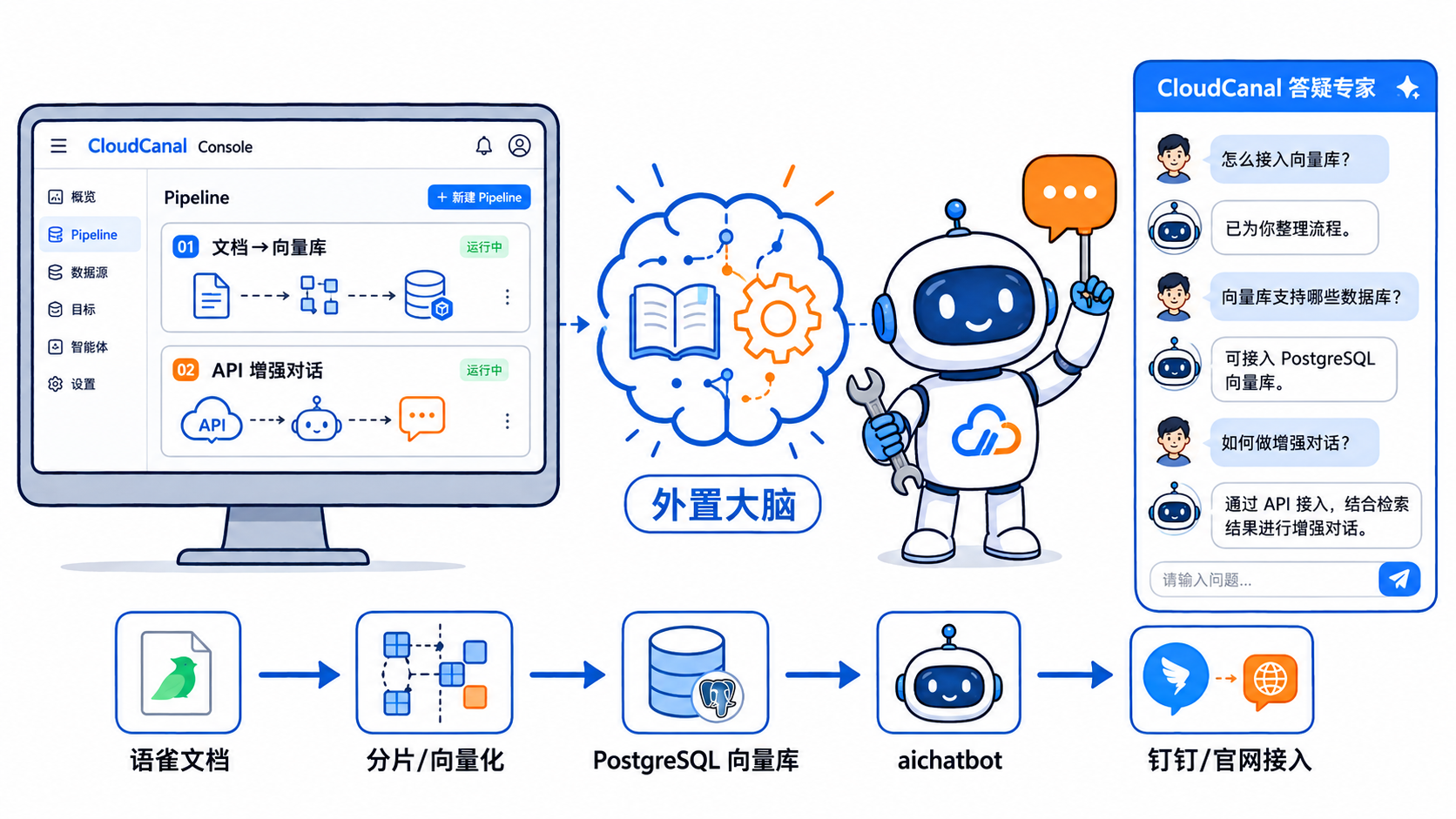
最开始,我们通过 CloudCanal 的两个任务,搭建了一套 Embedding + RAG 服务,第一个任务负责将文件或业务数据采集进来,经过分片、向量化后写入向量数据库;第二个任务则对外提供一个增强对话的 API 地址,用户可以通过这个地址接入自己的 AI 应用,让 AI 拥有**“外置大脑”**。
想象很“美好”,现实却很“骨感”。
回过头看,我们当时把这套能力做得太“极客”、也太“通用”了。它在技术上看起来很完整:有数据接入,有向量化,有检索增强,也有 API 服务。但问题在于,这个 RAG 服务到底应该解决什么具体场景、为谁创造价值、用户为什么要用它,我们其实并没有真正想清楚。
后来我们把视角拉回到自己的日常工作中,团队每天都会在社区、客户群中反复“答疑”,而这些问题背后,往往都依赖大量产品文档、使用经验、历史案例和排障知识,这个场景天然适合 RAG。于是我们决定先从自己开始,既当用户,也当开发者,基于这套能力做一款真正能解决问题的产品:一个面向 CloudCanal 的答疑“专家”。
在内部产品孵化阶段,这个项目最初的代号叫 clougence-aichatbot,重点其实落在后半段——AI 聊天机器人。
最初,aichatbot 与 CloudCanal 任务耦合得比较深,当时的核心思路相对直接:将我们内部沉淀的 FAQ,也就是语雀文档,通过 CloudCanal 任务完成分片、向量化,并最终写入 PostgreSQL 向量库,aichatbot 服务基于向量相似度检索,为大模型提供一个可检索、可引用的**“外置大脑”**。
这个过程并不轻松,受限于当时 Coding Agent 还不够成熟,很多代码工作仍然依赖“古法编程”一点点推进,直到 25 年 6 月,我们终于正式上线了 aichatbot。
从用户视角看,最初的产品形态其实就是一个普通的聊天机器人;稍微特别一些的地方在于,它是一个带有 CloudCanal 知识能力的聊天机器人,我们也陆续将 aichatbot 接入钉钉、公司官网等多个使用场景,开始让它真正进入内部和外部的业务流程。
Coding Agent
2025 年 12 月,Coding Agent 可谓百花齐放。Antigravity、Codex、Claude Code、Trae、Qoder……各家大厂相继推出了自己的 Coding Agent。
在此之前,我们受限于 Coding Agent 能力还不够成熟,加上团队本身也不是专业做 C 端产品出身,导致产品在 Q3、Q4 两个季度一直处于**“半推进、半放弃”**的状态。原因也很现实:人员不够,能力不够,精力也不够。
但这一年,Coding Agent 的能力开始快速跃迁。我也逐渐从“用 ChatGPT 辅助优化代码”,转向把越来越多完整的 Coding 任务交给 AI。但这一年,Coding Agent 的能力开始快速跃迁。我也逐渐从“用 ChatGPT 辅助优化代码”,转向把越来越多完整的 Coding 任务交给 AI。
坦白说,在这之前,我对 Coding Agent 始终保持怀疑。那时网络上把 Cursor 炒得很火,但我体验下来,感觉也不过如此。所以很长一段时间里,我对 Coding Agent 的态度都是“不太相信”。
直到 2025 年 11 月,Google Antigravity 发布。一开始,我依然带着怀疑的心态去体验。但这一次,我真的被 AI 惊讶到了。原来现在的 Coding Agent 已经强大到这种程度了。那一刻,我突然意识到:AI Coding 已经大势不可挡,未来它一定会成为程序员必须掌握的能力之一。
更重要的是,Google 一开始给出的 Pro 套餐几乎**“量大管饱”**。同年 12 月,我们决定将 clougence-aichatbot 正式更名为 Reakh。

Reakh
至今仍然清楚地记得那个早晨,2025 年 12 月 23 日上午,我们写下了 Reakh 的第一行代码。我并不清楚 Reakh 未来会走向哪里。它可能不会在历史长河中掀起任何浪花,也可能抵达一个我现在无法企及的高度,但在改名的那一刻,我们已经做出了一个明确决定:要把它打造成一款真正面向 C 端用户的产品。
这对我们来说并不容易,我们从来没有做过 C 端产品,没有现成经验,也没有成熟方法论,只能摸索着前进。我们研究了国内很多 AI Agent 产品,必须承认,他们做得非常不错。如果 Reakh 想要在其中找到自己的位置,就必须做出差异化。
最终,我们决定押注**“AI 团队”**能力。
我们希望用户面对的不只是一个单一 AI 助手,而是一个由不同专业领域“专家”组成的 AI 团队。用户只需要发起一个会话,就可以让多个专家围绕同一个问题协同工作,从不同角度给出判断、分析和解决方案。
与此同时,我们也观察到一个非常现实的问题:国内很多 AI 产品在复杂场景下依然会“说胡话”,也就是我们常说的“幻觉”。这种问题对程序员来说尤其痛苦,比如排查一个技术问题时,AI 会一本正经地给出结论,甚至附上几个看起来很专业的链接。结果点进去一看,全是 “404”。
我相信,这是每一位程序员都经历过的崩溃时刻。
Reakh 想解决的不只是“让 AI 能回答问题”,而是让 AI 在回答问题时更加可靠、更加可验证、更加贴近真实工作流,我们希望它不是一个只会聊天的 AI,而是一个真正能帮助用户完成任务、解决问题、降低不确定性的 AI 团队。

总结
对于现阶段来说,面对 AI,最重要的是多用、多试、多实践。只有用得多了,才知道它能做什么、不能做什么,哪些场景能提效,哪些场景不适合。AI 和过去学习走路、说话、读书、用电脑一样,本质上都遵循一个规律:熟能生巧。
不要被自媒体制造的焦虑牵着走。很多博主喜欢抛出争议话题,让大家吵来吵去。但 AI 时代更需要自己的判断力。与其焦虑观望,不如亲自下场,在真实场景中把它用起来。
💬 评论区